Enterprise artificial intelligence is rapidly evolving from experimentation into full-scale operational deployment, and Snowflake is making one of the industry’s largest infrastructure commitments to accelerate that transition.
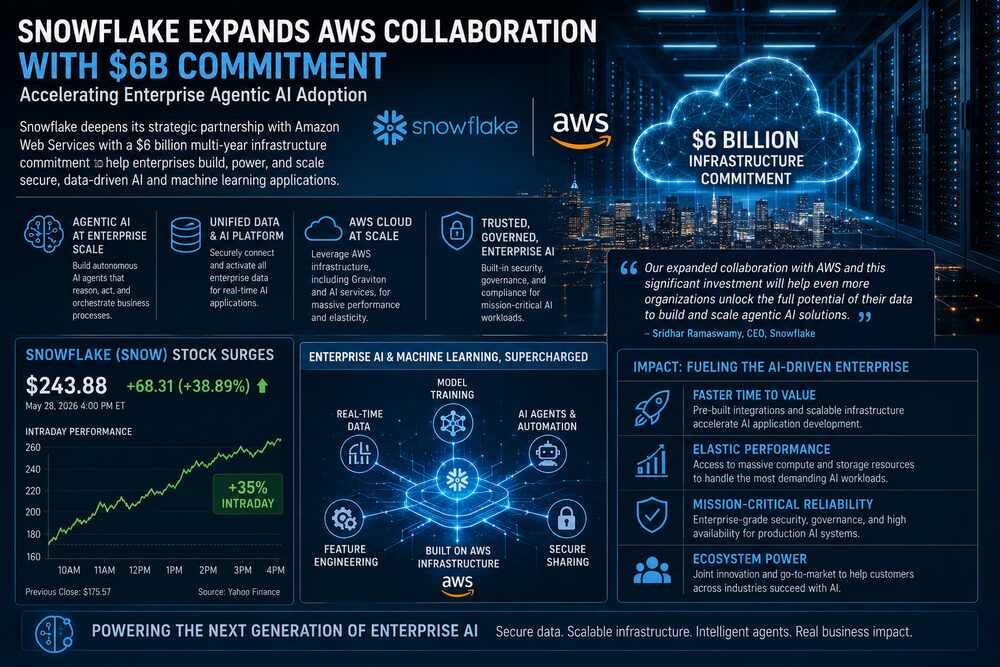
This week, the AI data cloud company announced an expanded strategic collaboration with Amazon Web Services, including a massive $6 billion multi-year infrastructure commitment to accelerate enterprise adoption of generative and agentic AI technologies.
The announcement immediately electrified investors. Snowflake’s stock surged more than 39% today following stronger-than-expected earnings and the AWS partnership expansion, marking one of the company’s strongest single-day market performances since its IPO.
For the supercomputing and enterprise HPC markets, the agreement represents something larger than a cloud partnership. It signals the emergence of AI-native enterprise infrastructure, in which massive-scale data platforms, hyperscale compute, and autonomous AI agents increasingly operate as a unified system.
From data warehousing to AI operating platform
Snowflake originally built its reputation as a cloud-native data warehousing company. But the modern AI race is forcing enterprise platforms to evolve far beyond analytics.
The new AWS agreement reflects that shift.
According to the announcement, the partnership focuses heavily on deploying “agentic AI” systems directly against enterprise data repositories, allowing organizations to build AI-driven applications that can reason over governed corporate datasets, automate workflows, and execute business processes securely at scale.
That distinction does matter.
Traditional enterprise AI systems primarily generated predictions or summaries. Agentic AI systems instead perform actions autonomously, orchestrating tasks, interacting with software systems, managing workflows, and continuously adapting using real-time enterprise data.
This dramatically increases infrastructure demands.
Unlike consumer chatbots, enterprise agentic AI workloads require:
- Persistent access to structured and unstructured corporate data
- High-throughput cloud storage systems
- Distributed GPU and AI accelerator resources
- Low-latency inference pipelines
- Fine-grained governance and security controls
- Continuous orchestration across thousands of simultaneous tasks
These are effectively supercomputing-scale operational problems being pushed into mainstream enterprise IT.
Why AWS matters
Snowflake’s decision to commit $6 billion to AWS infrastructure is not merely a purchasing agreement, it is a strategic acknowledgment that enterprise AI adoption will require hyperscale compute capacity on a sustained basis.
The company specifically highlighted growing enterprise demand for AI and data workloads running on AWS, including Graviton compute infrastructure and AI processing services.
This reflects a broader trend across the AI industry: compute-intensive machine learning is increasingly consuming cloud infrastructure at a scale once associated primarily with scientific supercomputing centers.
Enterprise AI deployment now depends on many of the same architectural principles that drive modern HPC systems:
- Massive parallel processing
- Distributed memory management
- High-bandwidth data pipelines
- Accelerator-rich architectures
- Scalable orchestration frameworks
- Optimized interconnect performance
The boundary between enterprise cloud computing and supercomputing is steadily dissolving.
Enterprise AI is entering its production phase
The market reaction suggests investors increasingly believe enterprise AI spending is shifting from pilot projects to production-scale deployment.
Snowflake reported strong fiscal Q1 2027 results alongside the AWS announcement, helping trigger the stock rally. Analysts cited accelerating AI demand, rising customer adoption, and expanding enterprise workloads as key growth drivers.
As of today, Snowflake shares traded near $244, up dramatically from the prior close of around $175.
The rally is particularly notable because Snowflake spent much of the past year under pressure amid concerns about slowing cloud optimization spending and intensifying competition in enterprise AI infrastructure.
This week’s announcement may mark a turning point.
Rather than treating AI as an optional product layer, Snowflake is positioning itself as foundational infrastructure for enterprise machine intelligence.
What this means for supercomputing
For the HPC and supercomputing industry, Snowflake’s AWS expansion highlights several important trends.
1. Enterprise AI is becoming an HPC workload
Historically, supercomputing centered around scientific simulations, defense research, genomics, and climate modeling.
Today, enterprise AI increasingly operates at a similar computational scale.
Training and orchestrating autonomous AI systems across enterprise datasets requires enormous distributed compute resources, often involving GPU clusters comparable to those used in traditional HPC environments.
This creates new opportunities for HPC technologies to migrate into enterprise infrastructure markets.
2. Data gravity is becoming a competitive advantage
The AI market is discovering that models alone are insufficient.
Competitive advantage increasingly comes from proximity to large, governed, continuously updated enterprise datasets.
Snowflake’s strategy leverages this principle directly by integrating agentic AI capabilities alongside enterprise data storage and analytics pipelines.
In practice, this means future enterprise AI platforms may resemble tightly integrated supercomputing environments where storage, compute, inference, and orchestration are deeply unified.
3. AI infrastructure spending is accelerating
The sheer scale of the AWS commitment illustrates how quickly enterprise AI infrastructure spending is escalating.
A $6 billion infrastructure agreement would once have been associated primarily with hyperscalers or national-scale HPC deployments.
Now, enterprise AI vendors are making comparable commitments to secure long-term compute capacity.
This trend is likely to accelerate demand for:
- AI accelerators
- High-bandwidth memory
- Advanced networking
- Liquid cooling systems
- Data center expansion
- Energy-efficient compute architectures
The beneficiaries extend far beyond cloud software companies.
Security and governance become central challenges
The rise of enterprise agentic AI also introduces significant governance challenges.
Recent academic research has increasingly focused on accountability, orchestration security, and zero-trust architectures for autonomous AI agents operating inside enterprises.
This is especially relevant as AI systems gain the ability to interact directly with sensitive enterprise systems and execute operational tasks autonomously.
Snowflake’s emphasis on governed enterprise data may therefore become a major differentiator in a market where trust, compliance, and auditability are becoming as important as raw model capability.
The emerging AI infrastructure stack
The broader significance of the Snowflake-AWS partnership is that it reveals how the enterprise AI stack is evolving.
The next generation of enterprise computing will likely combine:
- Hyperscale cloud infrastructure
- Distributed AI accelerators
- Real-time data platforms
- Autonomous AI agents
- HPC-inspired architectures
- Continuous orchestration layers
In effect, enterprises are beginning to build private AI supercomputing environments embedded directly into operational business systems.
That transformation could become one of the largest infrastructure shifts since the rise of public cloud computing itself.

