A new announcement touting one of the “world’s largest” quantum circuit simulations has reignited excitement around the convergence of supercomputing and quantum chemistry. But beneath the headline achievement lies a more complicated, and perhaps more sobering, reality about the limits of simulation-driven progress.
Researchers from the University of Osaka, working with Fixstars Corporation, report running quantum circuit simulations on up to 1,024 GPUs, surpassing the long-standing barrier of roughly 40 qubits in quantum chemistry simulations.
At first glance, the milestone appears to mark a leap toward practical quantum computing. A closer look suggests it may instead highlight just how far the field still has to go.
Bigger Simulations, Familiar Constraints
The team’s work centers on simulating quantum phase estimation (QPE), a foundational algorithm expected to underpin future quantum chemistry applications, including drug discovery and materials science.
Using a specialized simulator and a highly optimized parallel computing strategy, the researchers modeled systems such as:
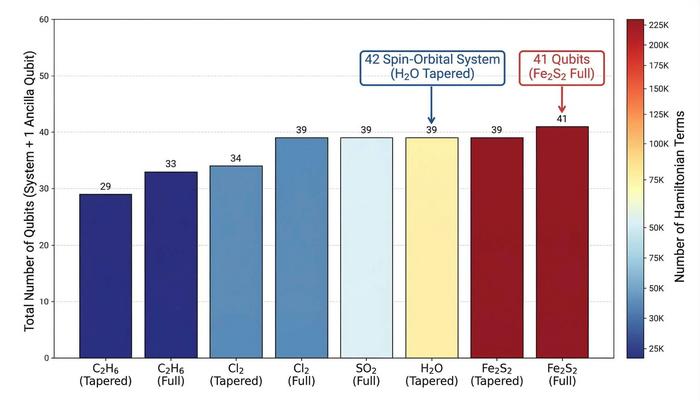
- A 42-spin-orbital water molecule system
- A 41-qubit circuit for an iron-sulfur molecule
These are, by current standards, impressive numbers, but still fall short for real-world industrial chemistry problems, which require larger and more complex quantum systems.
Even more telling is that the simulations required massive GPU clusters and careful optimization just to reach these sizes.
Simulating quantum advantage depends on classical brute force, now more than ever.
The Paradox of Quantum Simulation
There is an inherent irony at the heart of this work. The ultimate goal is to build quantum computers that outperform classical machines. Yet today, progress depends on ever-larger classical supercomputers simulating quantum behavior.
This raises an uncomfortable question: Are these simulations accelerating quantum computing, or quietly exposing its current impracticality?
The study itself acknowledges the challenge. Running these simulations required overcoming inter-GPU communication bottlenecks and operating within strict compute time limits, underscoring how resource-intensive the process remains.
For now, classical systems are not just a stepping stone; they are doing nearly all the heavy lifting.
Benchmarking vs. Breakthroughs
Proponents argue that such simulations are essential for benchmarking and validating quantum algorithms before real quantum hardware matures.
That may be true. But benchmarking is not the same as breakthrough.
Despite the scale of the computation, the work does not yet demonstrate:
- A clear path to quantum advantage in chemistry
- Practical workflows that outperform classical methods
- A reduction in the enormous computational cost required
Instead, it reinforces a pattern seen across the field: progress is measured in incremental increases in qubit counts, achieved through exponential increases in classical computing effort.
Supercomputing’s Expanding Role, And Its Limits
From a high-performance computing perspective, the achievement is undeniably significant. Coordinating 1,024 GPUs to simulate quantum circuits represents a triumph of parallel computing, software optimization, and systems engineering.
But it also underscores a critical tension.
Supercomputers are increasingly being used not just to solve scientific problems, but to simulate technologies that do not yet exist at scale. This places HPC in an unusual position, both enabling and compensating for the limitations of quantum hardware.
As simulations grow larger, so too do their costs, complexity, and energy demands. The question becomes not just what is possible, but what is practical.
A Measured View of Progress
There is no doubt that this work advances the technical frontier of simulation. It expands the range of quantum systems that can be studied and provides valuable testing grounds for future algorithms.
But the broader narrative, that such efforts are rapidly ushering in an era of quantum-enabled drug discovery or materials design, may be premature.
For now, the reality is more grounded: Supercomputers are still carrying the burden of quantum ambition.
And while that burden is pushing HPC to new heights, it also serves as a reminder that the quantum future remains, at least for now, largely theoretical.