

 How to resolve AdBlock issue?
How to resolve AdBlock issue? 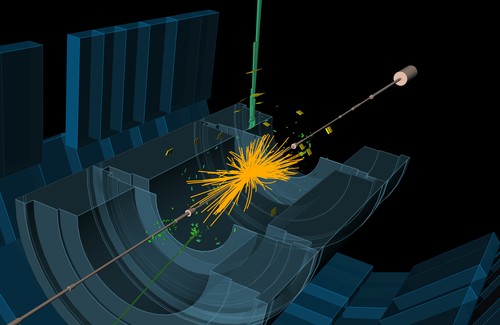
High-energy particle physics is built on two essential foundations: cutting-edge accelerators and advanced computational techniques. Researchers at the Institute of Nuclear Physics Polish Academy of Sciences, have now introduced a novel method that promises to greatly enhance the reliability of large-scale simulations, interpreting results from experiments like those at the Large Hadron Collider. This breakthrough holds significant promise for the supercomputing community.
A central challenge remains: how can computational physicists estimate the effects of calculations that are prohibitively resource-intensive to perform?
When Computation Meets the Limits of Physics
Modern particle physics experiments generate enormous datasets describing the aftermath of high-energy proton collisions. To interpret these events, scientists must compare experimental observations with theoretical predictions derived from complex numerical simulations based on quantum chromodynamics (QCD) and the Standard Model.
But the calculations required to simulate these interactions grow explosively in complexity. Perturbation theory, the mathematical framework typically used, expresses results as a series of corrections. Each successive order in the series represents a more precise description of the physics, but also requires dramatically more computational effort.
For large-scale collider simulations, computing higher-order corrections can become computationally prohibitive, even on modern HPC systems. As a result, physicists usually truncate the series after a manageable number of terms and then estimate the uncertainty introduced by the missing higher-order contributions.
The question, however, remains difficult: How large are the effects of the corrections that were never computed?
A New Approach to Estimating the Unknown
Physicists Matthew A. Lim of the University of Sussex and Dr. René Poncelet of IFJ PAN have proposed a new methodology for estimating these missing higher-order effects in perturbative calculations. Their work, published in Physical Review D, introduces a refined technique based on varying so-called nuisance parameters rather than relying solely on the traditional renormalization-scale variation method.
In the standard approach, theorists adjust the renormalization scale, a parameter linked to the energy scale of particle interactions, to evaluate how sensitive simulation results are to changes in that value. This variation provides a rough estimate of theoretical uncertainty.
The new method instead explores variations in physically interpretable parameters such as particle masses, coupling constants, or probability distribution functions. Because these quantities correspond more directly to measurable physics, the resulting uncertainty estimates can be less arbitrary and more grounded in experimental constraints.
For supercomputing engineers familiar with numerical modeling, the strategy resembles sensitivity analysis performed on large-scale simulations: perturb inputs within physically meaningful ranges and observe how the system responds.
Validating Against Real Collider Data
The researchers tested their framework across ten categories of proton-collision processes observed at the LHC. These included phenomena such as Higgs boson production, W and Z boson pair production, heavy-quark pair formation, and interactions generating gamma quanta and hadronic jets.
In cases where the traditional scale-variation approach already performed well, the new method yielded comparable results. However, in previously problematic scenarios, the nuisance-parameter technique produced more realistic uncertainty estimates, improving agreement between theoretical predictions and experimental observations.
According to Dr. Poncelet, the method offers a practical framework for estimating the impact of higher-order corrections in perturbative calculations, a capability that could sharpen the interpretation of collision data from both current and future accelerators.
Why This Matters for HPC
For the supercomputing community, the significance of the work extends beyond particle physics theory.
Large-scale collider simulations already consume vast computational resources across distributed HPC infrastructures worldwide. As researchers push toward higher precision, especially in the search for subtle deviations from the Standard Model that might signal new physics, computational demand continues to escalate.
Methods that improve the statistical reliability of truncated simulations can reduce the need for prohibitively expensive higher-order calculations while still preserving scientific accuracy. In other words, smarter mathematical frameworks can complement brute-force computing.
This interplay between algorithmic innovation and HPC capability is becoming increasingly central to modern scientific discovery. Even with the world’s fastest supercomputers, physicists cannot compute everything. The art lies in determining what must be calculated, what can be approximated, and how to quantify the difference.
Toward More Precise Digital Experiments
As next-generation particle accelerators and upgraded detectors deliver increasingly precise experimental data, theoretical models must advance alongside them. Improved methods for estimating uncertainty, such as the approach proposed by Lim and Poncelet, offer a practical way to keep simulations aligned with observations without demanding impractical levels of computational power.
For HPC engineers working at the intersection of physics and large-scale computation, the lesson is both technical and conceptual: improving simulations is not solely about building faster machines. It also requires better strategies for understanding and quantifying the uncertainties embedded within the equations that drive those simulations.



