

 How to resolve AdBlock issue?
How to resolve AdBlock issue? 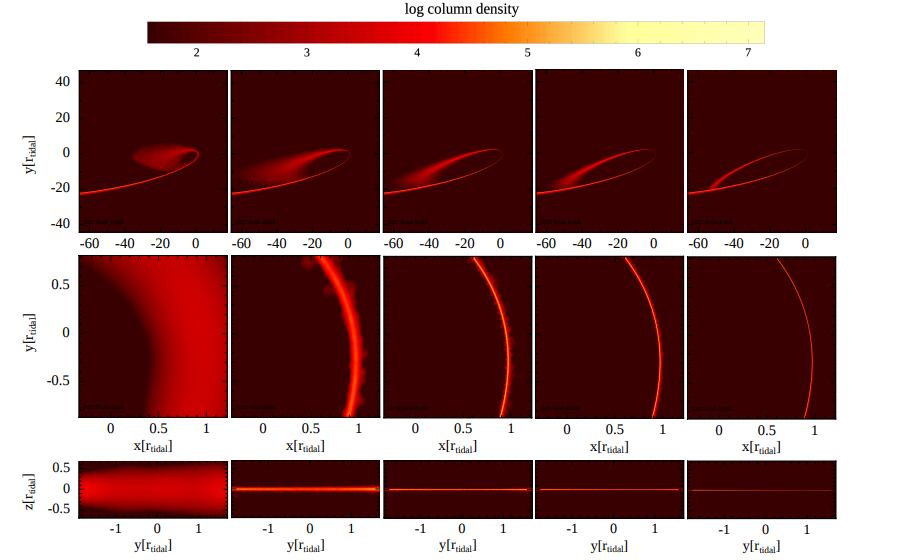
Amid the infinite darkness of space, a silent catastrophe unfolds.
A star wanders perilously close to a supermassive black hole. Gravitational forces stretch and tear it apart, transforming the star into a radiant stream of stellar debris that spirals into oblivion. For a fleeting instant, the cosmos ignites, producing a phenomenon known as a tidal disruption event (TDE).
These violent encounters are among the most powerful probes of black holes. But until now, scientists may have been misunderstanding what actually happens in those crucial first moments after destruction.
It took supercomputing at an unprecedented scale to see the truth.
Simulating a cosmic catastrophe
In a new study published in The Astrophysical Journal Letters, researchers have used cutting-edge simulations to recreate the fate of a Sun-like star destroyed by a black hole one million times more massive than our Sun.
But this was no ordinary simulation.
Using a GPU-powered code known as SPH-EXA and running on the ALPS supercomputer, the team modeled the event with up to 10 billion particles, orders of magnitude beyond previous efforts.
This level of detail matters. In TDEs, the physics spans extremes: from the size of a star to orbits stretching tens of thousands of stellar radii, and from minutes-long stellar collapse to debris returning weeks later.
Capturing all of it requires immense computational precision.
Supercomputers, in this case, are not just tools; they are the only way to observe the unobservable.
A long-standing theory falls apart
For years, scientists believed that as the shredded stellar material swings back toward the black hole, it undergoes intense compression near its closest approach, creating powerful “nozzle shocks” that rapidly heat and spread the debris.
This process was thought to play a key role in forming the bright, glowing disk of material that ultimately feeds the black hole.
But the new simulations tell a different story.
As the resolution increased, a key finding emerged: the dramatic spreading of the debris disappeared, and at the highest resolution, the returning stream stayed narrow and largely undisturbed.
Even more striking, the simulations showed that the amount of energy lost to shocks dropped to almost nothing, just one hundred-thousandth of the material’s kinetic energy. This finding directly challenges previous ideas about how the debris behavior was understood.
What once appeared to be a fundamental physical process now looks, in part, like a numerical illusion.
The power, responsibility of supercomputing
This revelation underscores a deeper truth about modern science: resolution is not just a technical detail. It can fundamentally change our understanding of reality.
Lower-resolution simulations had suggested a universe where stellar debris violently disperses near the black hole. Higher-resolution, supercomputer-driven models reveal a more delicate picture, one where the debris remains coherent, awaiting a different mechanism to evolve.
That mechanism, the study suggests, is likely stream to stream collision: where incoming and outgoing flows of stellar material intersect and dissipate energy more gradually.
It is a subtle shift, but one with major implications for how we interpret cosmic observations.
Reading the light of shredded stars
These insights arrive at a critical moment.
Astronomers are increasingly using tidal disruption events as tools to study otherwise invisible black holes. Each flare carries information about the black hole’s mass, spin, and environment.
But decoding those signals depends on understanding the physics behind them.
If the early stages of these events are governed not by violent shocks but by more structured, collision-driven processes, then the light we observe may tell a more nuanced story, one shaped by geometry, orbital dynamics, and relativistic effects.
In other words, every shredded star becomes a kind of message.
And supercomputing helps us learn how to read it.
Toward a new era of precision astrophysics
What makes this work inspiring is not just its findings, but its method.
By pushing simulations to billions of particles and leveraging advanced GPU architectures, researchers are entering a new regime of precision astrophysics, where numerical artifacts give way to physical truth.
It is a reminder that the universe does not yield its secrets easily. Sometimes, the difference between misconception and discovery is measured not in theory, but in computational power.
A universe reconstructed in code
We may never witness a star being torn apart up close.
But through supercomputing, we can reconstruct the event in astonishing detail, following every fragment, every orbit, every interaction as gravity does its work.
And in doing so, we move closer to answering one of the most profound questions in astrophysics:
What really happens when matter meets the edge of a black hole?
Thanks to the growing power of supercomputing, the answer is no longer beyond our reach.



