

 How to resolve AdBlock issue?
How to resolve AdBlock issue? 
Scientist’s vision transformed the way researchers analyze data, access biomedical information
The 2023 Warren Alpert Foundation Prize has been awarded to scientist David J. Lipman for his visionary work in the conception, design, and implementation of computational tools, databases, and infrastructure that transformed the way biological information is analyzed and accessed freely and rapidly around the world.
The Warren Alpert Foundation bestows the $500,000 award in recognition of work that has improved the understanding, prevention, treatment, or cure of human disease. The prize is administered by Harvard Medical School.
Lipman will be honored at a scientific symposium on Oct. 11, 2023, hosted by HMS. For further information, visit The Warren Alpert Foundation Prize symposium website. 
Lipman, who is currently a senior science adviser for bioinformatics and genomics for the Food and Drug Administration, is receiving the award for work he did in the 1980s and 1990s before and after becoming the founding director of the National Center for Biotechnology Information (NCBI), a position he held until 2017.
Lipman led the development of a powerful computational program called BLAST for the analysis and comparison of newly identified DNA and protein sequences against all known DNA and protein sequences. The tool transformed researchers’ ability to access and interpret DNA, RNA, and protein sequence data and propelled the fields of computational biology and molecular biology. While at the NCBI, Lipman also conceptualized and then oversaw the design and implementation of PubMed, the web-based database for biomedical literature used daily by millions of scientists, physicians, students, teachers, and the public. Today, NCBI houses multiple biotechnology databases and resources that, over the years, have reshaped biology, medicine, and other fields of science.
“At a time when computation was deemed an exotic pursuit by most biomedical researchers, David was prescient because he understood the potential of computation to propel biomedical science forward,” said George Q. Daley, dean of HMS and chair of the Warren Alpert Foundation Prize scientific advisory board. “His vision, creativity, and rigor have transformed how scientists analyze and share data and, indeed, how we do science.”
Lipman’s pioneering achievements not only democratized access to scientific information but also helped catalyze critical discoveries by enabling vital exchanges and collaborations among scientists in multiple fields of biomedicine and beyond.
“The foundational work of David Lipman in the field of computational biology and the tools that he envisioned and created have an impact that is nearly impossible to measure on the fields of biology, medicine, and beyond,” said David M. Hirsch, director, and chairman of the board of The Warren Alpert Foundation. “His contributions exemplify the mission and vision of the Warren Alpert Foundation.”
Significance of the work
Over the past 40 years, advances in DNA sequencing, computation, and the internet have transformed biomedical research, public health, and the practice of medicine. Lipman developed many of the most important computational tools and infrastructure for making discoveries with these technologies.
In the 1980s, as the understanding of DNA and genes accelerated, elucidating the evolutionary relationships across genes and proteins within and between species became a major focus of Lipman’s scientific curiosity and research efforts. Such knowledge is critical in elucidating evolutionary relationships that provide essential clues about the function of genes and proteins.
Early on, Lipman realized that the rapid emergence of new genetic sequencing data would require powerful and efficient computer programs to compare one DNA or protein sequence against all known sequences.
In a series of papers published between 1983 and 1990, Lipman pioneered the design of multiple methods for comparative sequence analysis. This culminated in the development of an algorithm called BLAST, described in a now seminal 1990 paper. Today, BLAST and subsequent programs, gapped BLAST, and PSI-BLAST remain among the most widely used tools in biology and medicine and are deemed among the most significant achievements in the field of computational biology of the past 40 years.
BLAST enabled understanding of the interplay between genes, biology, physiology, and the environment across organisms and has led to important discoveries in nearly all areas of biomedical research, from the molecular basis of cancer to identify the source of a foodborne outbreak.
Furthermore, Lipman became one of the most ardent supporters of and key figures in the move toward open-access science. He was instrumental in the design of PubMed, the open-access scientific publication resource of the NCBI and the largest and most widely used resource for scientific research in the world.
As director of NCBI, Lipman oversaw GenBank, the world’s largest DNA and protein sequence repository, an international collaboration among the United States, Japan, and Europe. Under his direction, NCBI brought GenBank into the era of genomics and the internet, vastly augmenting its capabilities.
“Through the creation of computational tools and information systems, my goal and that of the wonderful collaborators I've had the honor to work with has been to enable biomedical researchers to make discoveries. The scientists involved in the nomination and selection process have a deep understanding of the field and have themselves made some of the most important biomedical discoveries. So, this honor holds a special significance to me,” commented David J. Lipman.
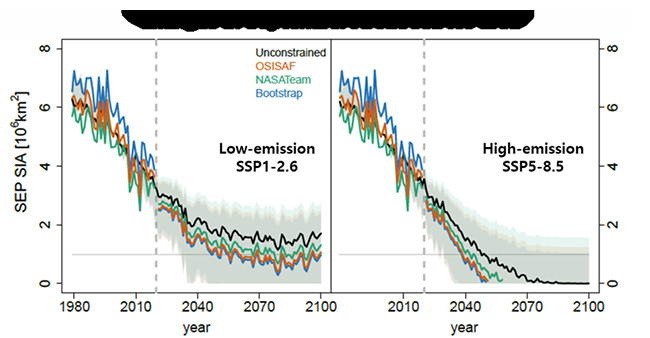

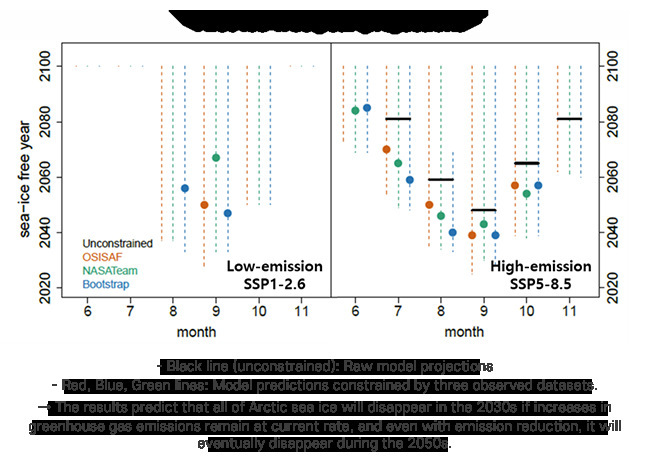
 or receiving signals (bottom row). Left: healthy controls; Middle: unresponsive wakefulness; Right: minimally conscious")
")